人脸追踪并实时打码
- 流程图
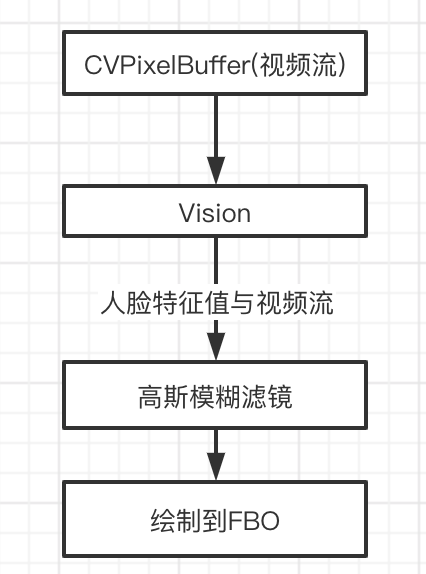
初始化视频输入流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28func setupVideo() {
session.sessionPreset = .hd1280x720
if let videoDevice = AVCaptureDevice.default(.builtInWideAngleCamera, for: .video, position: .front),
let input = try? AVCaptureDeviceInput.init(device: videoDevice){
//swift在videoDevice上设置帧率,oc是在AVCaptureVideoDataOutput设置帧率
videoDevice.activeVideoMinFrameDuration = CMTime(value: 1, timescale: 30)
session.addInput(input)
}else{
assert(true, "初始化失败")
}
let output = AVCaptureVideoDataOutput()
session.addOutput(output)
let videoOutputQueue = DispatchQueue.init(label: "videoOutputQueue")
output.setSampleBufferDelegate(self, queue: videoOutputQueue)
output.videoSettings = [String(kCVPixelBufferPixelFormatTypeKey):kCVPixelFormatType_32BGRA]
output.connections.forEach { (con) in
//注意此处设置视频方向,人脸为竖屏正向,与人脸识别出来的boundingBox不需要转化就是0~1的纹理坐标了
con.isVideoMirrored = false
con.videoOrientation = .portraitUpsideDown
}
session.startRunning()
}回调函数处理视频流,识别人脸
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection){
guard let buf = CMSampleBufferGetImageBuffer(sampleBuffer) else { return}
/// 1.新建侦测人脸request
let request = VNDetectFaceLandmarksRequest { (req, err) in
/// 4.得到处理结果:req.result即是识别出来的人脸
guard let results = req.results else {return }
var faceBounds :[CGRect] = []
for ob in results{
if let ob = ob as? VNFaceObservation {
/// boundingBox是识别出来的人脸框,以左下角为原点,值是0~1范围内,这里与视频的方向对应上了,所有不需要转化,传入shader中直接可以纹理坐标比较
faceBounds.append(ob.boundingBox)
}
}
DispatchQueue.main.async {
self.glview.renderCVImageBuffer(buf, normalsFaceBounds: faceBounds)
}
}
/// 2.新建处理handler,注意orientation的值和在设置数据输出时设置的视频的方向
let handler = VNImageRequestHandler(cvPixelBuffer: buf, orientation: .downMirrored)
do {
/// 3.发起人脸识别
try handler.perform([request])
} catch let err {
}
}高斯模糊
原理
以当前像素点为中心,根据二维高斯函数计算周围像素的权重,将对应像素与对应的权重相乘,在把这些值相加,即是该点高斯模糊后的像素值。参考网址
二维高斯函数
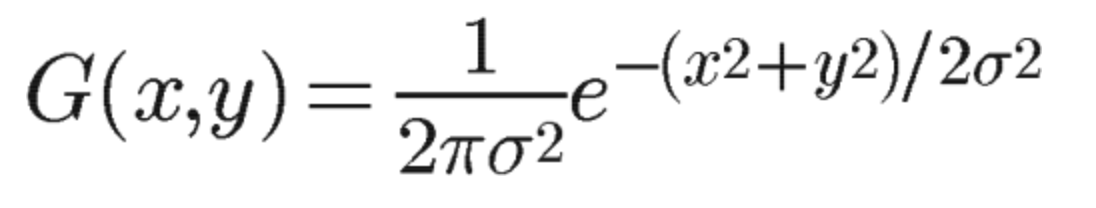
x,y表示像素点的坐标,G则是该像素的权重;从下图可以看出σ的值越大,周围的像素权重越高,可通过matlab(线上matlab)来验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19% 先限定三维图中的 x,y 轴坐标范围
X = -15 : 1 : 15;
Y = -15 : 1 : 15;
% 标准差
sigma = 5;
[ XX, YY ] = meshgrid( X, Y );
Z = ( XX ).^2 + ( YY ).^2; % 均值为(0,0)
Z = -Z / ( 2 * sigma^2 );
Z = exp(Z) / ( 2 * pi * sigma^2 );
% 显示高斯函数的三维图
subplot(1,2,1), mesh(X, Y, Z); % 线框图
title('σ=5');
sigma = 8;
[ XX, YY ] = meshgrid( X, Y );
Z = ( XX ).^2 + ( YY ).^2; % 均值为(0,0)
Z = -Z / ( 2 * sigma^2 );
Z = exp(Z) / ( 2 * pi * sigma^2 );
subplot(1,2,2), mesh(X, Y, Z); % 线框图
title('σ=8');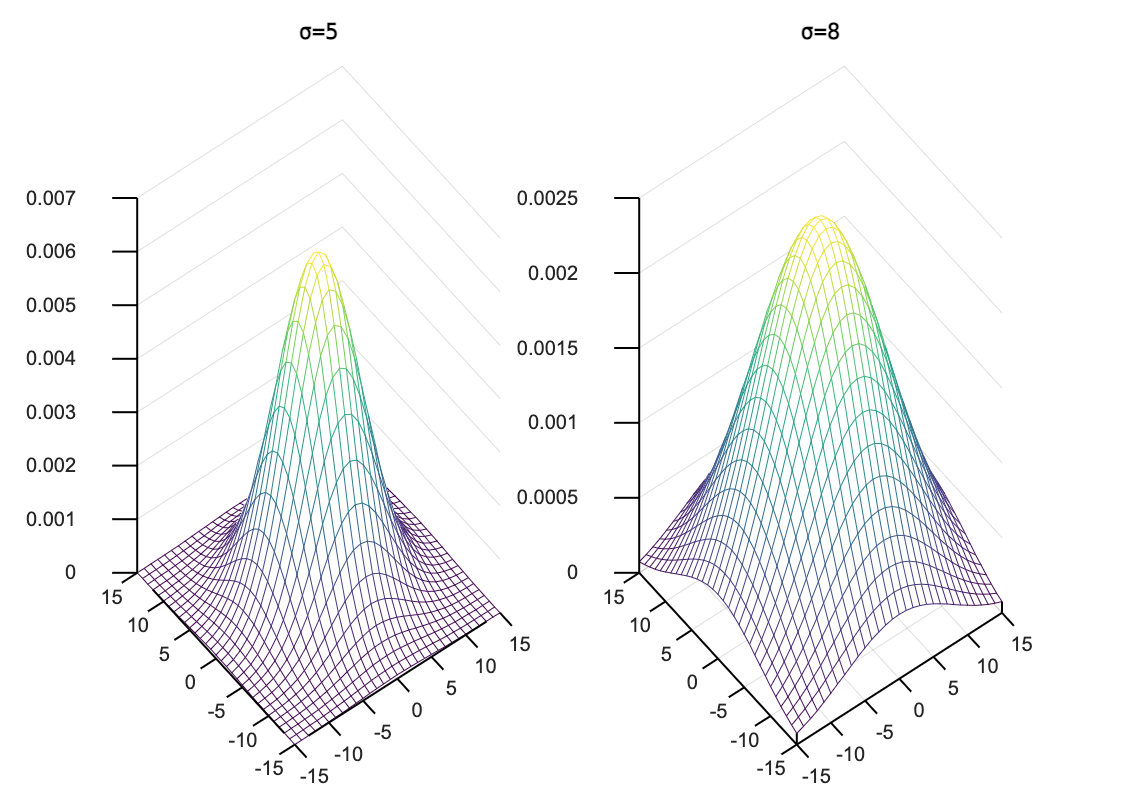
模糊半径为2的像素坐标
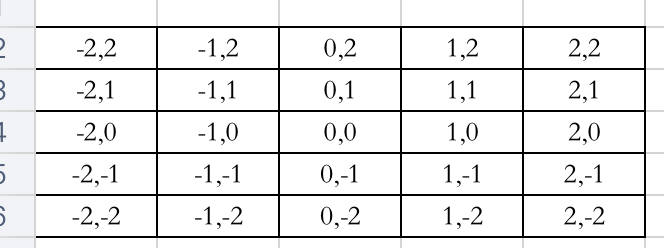 对应的权重是
对应的权重是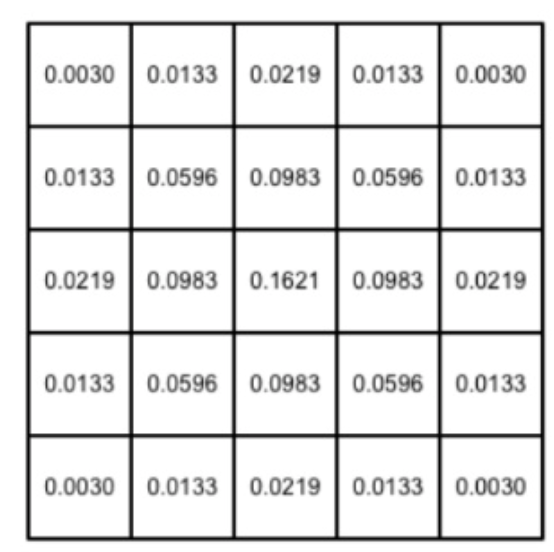
σ选的是1且是归一化的权重(将G(x,y)/∑G(x,y));将每个位置的与对应的权重相乘,再相加,则为像素点(0,0)的高斯模糊后的值;此种计算方法,对于一张w*h分辨率的图要进行 w* h*(radius*2+1)2计算
- 计算高斯模糊简化方法:先进行X轴高斯模糊,再进行Y轴高斯模糊

将每个像素以x轴的权重进行高斯模糊 C(0,0) = 0.0545*C(-2,0) + 0.2442*C(-1,0) + 0.4026*C(0,0) + 0.2442*C(1,0) + 0.0545*C(2,0)
再对x轴过滤的纹理进行y轴的过滤,因为每个像素已经对x轴方向上进行过加权平均了,在对y轴过滤时,会将每个像素值x轴的加权平均仍旧会影响以y方向的加权平均,算得结果和对像素进行(radius*2+1)2加权平均的值是一致的; 此中方法的计算量只需要 2 * (radius*2+1) * w*h次计算
编写shader
根据传入的模糊半径计算好权重, 选择合适的相邻像素的步长得到纹理的偏移数组;这里要特别注意:对于720*1280的视频数据,按照自己的理解,以当前像素为原点,认为偏移x轴上偏移一像素的步长是1/720, y轴方向偏移一像素的步长是1/1280,这样做以后,高斯模糊的效果很弱(加大模糊半径会加大计算量,半径设置10时已经卡到不能输出视频了),后面想着赋值纹理的时候是以mipmap的方式映射的,那么在以375宽度的手机尺寸,是否应该用mipmap生成的720*1280/4 的纹理,将x步长设置为1/360,y的步长设置为1/640,视频的模糊效果还是不理想。 经过测试选择了1/200作为步长,模糊的效果可以达到要求。 有小伙伴对这个步长有研究吗?只偏移一像素时,在转化为偏移的纹理坐标时,这个步长应该是1/720和1/1280吗?
因输入的纹理数据是ARGB,到shader里面访问时texture(tex,texCoord).rgba对应关系是 r->a, g->r, b->g, a->b
代码参见demo
设置opengl相关参数
代码参见demo
将脸部矩形框数据传入shader,并渲染到FBO呈现在屏幕上